
Text File Snippet
10x12 - Sunday, Cruddy Sunday
Quote
Post
by bunniefuu » 02/05/99 17:32
♪[ Chorus Singing ]
[ Bell Ringing ]
[ Whistle Blowing ]
[ Beeping ]
♪ [Jazzy Solo ]
[ Beeping ]
[ Tires Screeching ]
D'oh! [ Screams ]
[ All Gasp ]
[ Channel Changes ]
[ Snoring ]
[ Chattering ]
Hey, hey. Settle down, children.
Now, who's ever wondered how the post office works?
No one?
I did until we came here last year.
Ah, yes, last year. Anyway, look.
Here comes our guide for the day, Postmaster Bill.
[ Chuckling ] Howdy, partners.
We knew we wanted to look at the transcripts for the Simpsons and we knew it had to be online and the most up to date and usable site was this one that we pulled from. The texts were well formatted and seem to resemble the actual episodes.
Issues that immediately arose were that not every season was complete. Our original plan was to view the first 10 seasons to show change over time but one season was completely absent, and one was missing episodes. We figured our best course of action would be to take seasons that were around 10 years apart.
import requests
from bs4 import BeautifulSoup
# URL of the main page with links to each episode
main_url = 'https://transcripts.foreverdreaming.org/viewforum.php?f=431&sid=0695f7b460b8f09045f42e8fc4ea2456&start=702'
# Send a request to the main page and get the HTML response
main_response = requests.get(main_url)
# Parse the HTML content of the main page using BeautifulSoup
main_soup = BeautifulSoup(main_response.content, 'html.parser')
# Find all the links to each episode page on the main page
episode_links = main_soup.select('#wrap > div:nth-child(8) > div > ul > li > dl > dt > div > a.topictitle')
# Loop through each episode link and scrape the transcript text
for link in episode_links:
try:
# Get the URL of the episode page
episode_url = 'https://transcripts.foreverdreaming.org/' + link['href']
# Send a request to the episode page and get the HTML response
episode_response = requests.get(episode_url)
# Parse the HTML content of the episode page using BeautifulSoup
episode_soup = BeautifulSoup(episode_response.content, 'html.parser')
# Find the Div Container that contains the transcript text
transcript_div = episode_soup.find('div', {'class': 'postbody'})
# Get the text of the transcript
transcript_text = transcript_div.get_text()
# Get the season and episode number from the link text
link_text = link.get_text()
if link_text.startswith('01x'):
season_number = '1'
episode_number = link_text.split('-')[0][-2:]
else:
season_number = link_text.split('x')[0]
episode_number = link_text.split('x')[1]
# Create a filename for the transcript
filename = f'Season {season_number} Episode {episode_number}.txt'
# Write the transcript text to a file
with open(filename, 'w', encoding='utf-8') as f:
f.write(transcript_text)
print(f'{filename} saved successfully!')
except Exception as e:
print(f"Error occurred for episode {link_text}: {e}")
continue
print('Done processing all episodes.')
We needed to get the text files off the website in the most efficient manner and the code above is our most effective manner. We had to create a python script that would look through each of the seasons and only take 1, 10, 20, and 30 and then convert the certain HTML code in which the texts were stored and then turn that into a text file using the name of the episode and season.
It all sounds fine and dandy, like we just wrote out of the blue. But, it took a lot of time and Googling to figure it all out. It could’ve been faster to take all episodes and copy and paste them into separate text files but nah… this was way cooler!... but much harder.
XML File Snippet
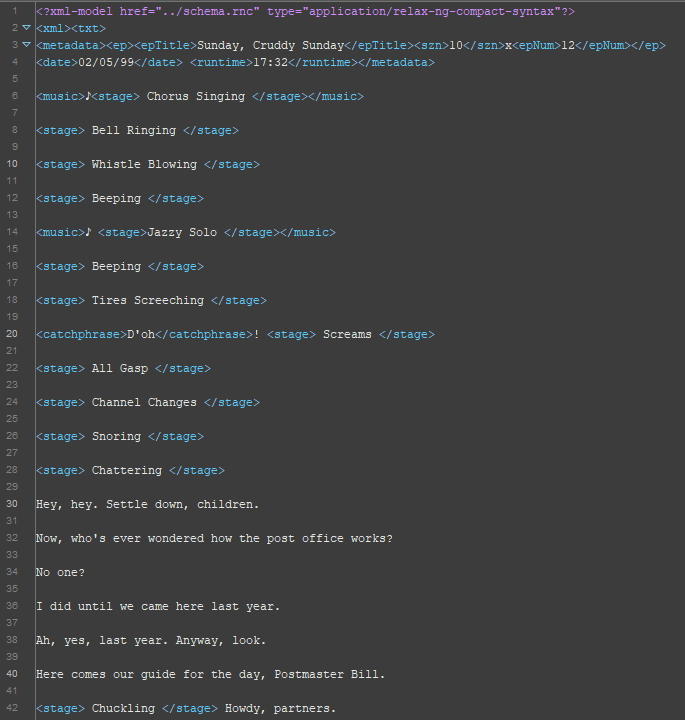
The XML was critical to actually find any numbers. We thought about it for about a week coming up with what we wanted to find and how exactly we wanted to do it and then we went with Finding and Replacing.
We still dealt with a lot of bugs in the words. Some are still around within the code. Things such as: foreign letter accents. ASCII characters. Just little things that really shot down some ideas that line counts and especially how Season 1 is a completely different setup than the others.
start = xml
xml = element xml {txt}
txt = element txt {metadata?, mixed{(stage | fam |music | catchphrase | person | location)*}}
metadata = element metadata {ep?, mixed { date* , runtime* , stage*}}
date = element date {text}
runtime = element runtime {text}
ep = element ep {mixed{(epTitle, szn, epNum)*}}
epTitle = element epTitle {mixed {fam* , person* , catchphrase* , location*}}
szn = element szn {text}
epNum = element epNum {text}
stage = element stage {mixed {fam* , location* , person*}}
fam = element fam {text | person*}
music = element music {mixed {stage* , location* , fam* , person*}}
catchphrase = element catchphrase {mixed {person*}}
person = element person {text}
location = element location {text}
The RNG Schema was used to set the structure of our XML files. The tag hierarchy was fairly simple and made up of a small set of tags which made our schema simple yet tag the information we needed for the project.
There was only one problem which came from working on the RNG Schema, the original draft had a few problems with mixed syntax which was easily fixed. With this problem solved the schema was complete with no other problems.
